引言
在java的IO系统中,对资源的操作分为两类:字节流与字符流。如果延承inputStream与outputStream就是字节流,如果延承reader与writer就是字符流,那么他们之间到底有什么区别呢?在本篇博文中会列出IO系统的所有操作类的框架,并对字节流与字符流做出详细的解释,最后会用一些demo来分别实现字节流与字符流的操作。笔者目前整理的一些blog针对面试都是超高频出现的。大家可以点击链接:http://blog.csdn.net/u012403290
流
“流”是IO系统中的核心抽象概念。它代表任何有能力产出数据的数据源对象或者是有能力接收数据的对象。它屏蔽了IO设备中处理数据的细节。在IO系统中,我们对资源的处理都是以流的形式操作的,流中保存的其实是字节文件。
一个语法糖 try-with-resource
我们知道在把资源作为一个对象的时候,都不能忘记最后的close操作。那如何断定一个对象是资源对象呢?一般的,如果一个类实现了java.io.Closeable对象的话,那么它就是一个资源对象。比如说我们讨论的IO系统:
//InputStream
public abstract class InputStream implements Closeable {
}
//OutputStream
public abstract class OutputStream implements Closeable, Flushable {
}
//Writer
public abstract class Writer implements Appendable, Closeable, Flushable {
}
//Reader
public abstract class Reader implements Readable, Closeable {
}上面就是IO系统的关键类,他们都实现了Closeable对象,所以当已他们为对象时,都需要在结束的时候关闭资源。
在JDK1.7时引入了try-with-resource这一种新的语句,它可以在你使用资源的时候,就不需要手动关系,java会自动来关闭它。在这之前,我们一般用try-catch-finally来控制抛错与关闭,我们会在finally语句块中进行资源的关闭。比如说下面这段代码:
package com.brickworkers.io;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class FileReadTest {
public static void main(String[] args) throws IOException {
File old = new File("F:/java/io/write.txt");
//老方法对资源进行读取
InputStream in = new FileInputStream(old);
byte[] bs = new byte[(int) old.length()];
try {
in.read(bs);
}finally{//我们必须在finally中对资源进行关闭
in.close();
}
System.out.println(new String(bs));
//try-with-resource对资源进行读取
try(InputStream in2 = new FileInputStream(new File("F:/java/io/write.txt"))){//会自动关闭资源,我们把资源放入try的括号中
in2.read(bs);
}
System.out.println(new String(bs));
}
}
java IO系统整体框架
下面这张图是从别人的博客上摘过来的,总结的很好:
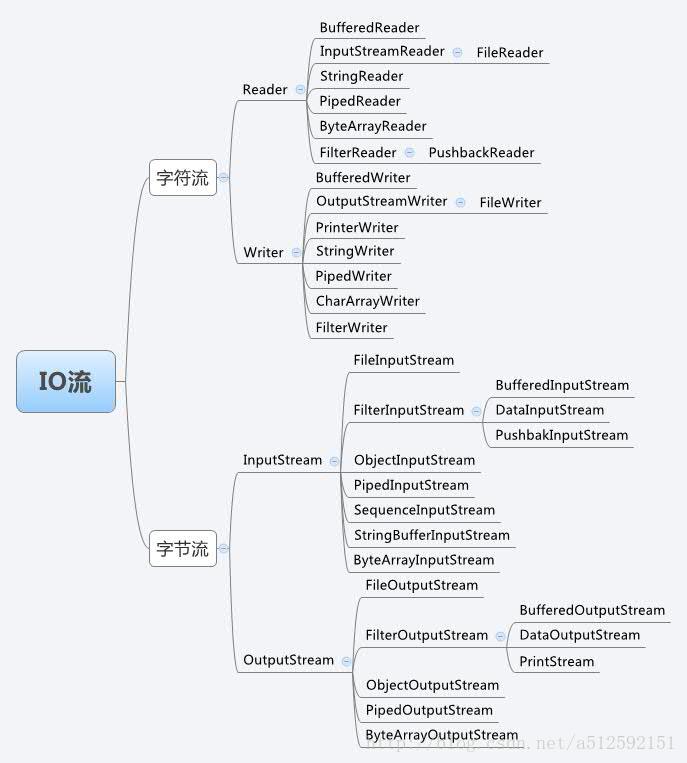
对于字节流来说,在上篇博文中,我们已经纤细介绍过他们的父类,子类,装饰类之间的关系。FilterInputStream与FilterOutputStream就是两个装饰类,他们可以把流转变成一个更加适合的方式来展现,如果对装饰者模式不是很了解,请参考上一篇博文:http://blog.csdn.net/u012403290/article/details/71747516
每一个子类都有它所对应的功能,在后面的章节中,我们会详细的介绍每一个子类的核心功能。在本篇博文中,上面这张图,我想说明的是存在两个派别:字节流与字符流。
为什么已经存在字节流还要引入字符流
熟悉java的应该知道,字节流比字符流产生的更早,可以说jdk一面世,已经有字节流了。那么为什么后面又引入了字符流呢?
首先,各个单位之间的关系,我们要清楚:
字节我们用Byte做单位,位我们用bit做单位,这就是大小b的关系
1字节(B) = 8位(b)
1字符 = 2字节(B) = 16位(b)
然后国际化的Unicode编码是16位的,也就是占2个字节,或者1个字符。那么我们简单的用字节流来处理Unicode编码,就显得非常鸡肋,所以字符流也就应运而生了。同时,使用字符流操作会比字节流操作更加的迅速,为什么会更加迅速呢?一个最显然的加速方式就是缓存区。字符流是用了缓存区的,而字节流是直接与文件进行操作。以下是一个典型的试验,用两者方式输出一个文件,但是都不关闭流,如果存在缓存区的话,那么它的触发机制就是流关闭导致它的缓存结束:
package com.brickworkers.io;
import java.io.File;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.OutputStream;
import java.io.Writer;
public class FileReadTest {
public static void main(String[] args) throws IOException {
File file1 = new File("F:/java/io/write1.txt");
//字节流输出
OutputStream os = new FileOutputStream(file1);
String txt = "helloworld";
try{
os.write(txt.getBytes());
}finally{
//不关闭流
}
File file2 = new File("F:/java/io/write2.txt");
Writer writer = new FileWriter(file2);
try{
writer.write(txt);
}finally{
//不关闭流
}
}
}
运行结果你会发现:使用字节流的在文本文件中已经写入了hello world,但是字符流却没有写入,说明字符流是带有缓存区的,这个时候就需要刷新缓存区,或者关闭流来触发输出。不要在输入流用不关闭流来进行上述测试,试想一下不管存不存在缓存区,你数据读取了,那么就都会是有了的,并不会收缓存区影响。
当然,并不是说摒弃字节流全部都使用字符流,在很多情况下字符流是不能用的,什么情况呢?指定字节操作的时候就不可以用字符流。前面说过,所有的资源都是以字节的形式存储的,包括图片,视频,音频等等,所以在日常的开发中字节流的操作还是非常普及的。
两个流派进行转化
一个面向字符流,一个面向字节流。那么他们之间在JDK中是如何转化的呢?Reader与Writer中有两个类来处理这种转化,他们分别是InputStreamReader与OutputStreamWriter,可以称这两个为适配器类。可以在上面的图片中找到他们。下面就是他们的一个使用例子:
package com.brickworkers.io;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.io.Writer;
public class FileReadTest {
public static void main(String[] args) throws IOException {
File file = new File("F:/java/io/write.txt");
//字节流输出
OutputStream os = new FileOutputStream(file);
String txt = "hello world";
//把字节流转化成字符流操作
Writer writer = new OutputStreamWriter(os);
try {
writer.write(txt);
} finally{
writer.close();
}
}
}
或许有小伙伴要问了,那么上面的代码字节流转化成字符流是实现了。那如果我要字符流转成字节流呢?其实也很简单,我们可以先把char转化成String,然后我们用String的API中的getBytes方法转化成字节。然后再使用字节流处理。
编码问题
在实际的开发中会经常遇到编码的问题,尤其是对中文的处理,经常会导致乱码。那么有什么办法能很好的避免这个问题呢?
博主在IO系统中,为了更好的避免乱码,如果只对于上述的知识之内,一般采用先用字节流获取要处理的文件,然后把字节流用适配器(OutputWriter与InputReader)来转化成字符流,这个时候就可以设置他们的编码规则,请参考下面这段代码:
package com.brickworkers.io;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
public class FileReadTest {
public static void main(String[] args) throws IOException {
//在write.txt文件中,我写了一段中文
File file = new File("F:/java/io/write.txt");
//尝试用字节流
byte[] bs = new byte[(int) file.length()];
try(InputStream in = new FileInputStream(file)){
in.read(bs);
}
System.out.println("字符流:" +new String(bs));
//尝试用字符流
char[] ch = new char[(int) file.length()/2 - 2];
try(Reader reader= new FileReader(file)){
reader.read(ch);
}
System.out.println("字符流:" + new String(ch));
//两者组合操作
char[] res = new char[(int) file.length()/2 - 2];
try(Reader reader = new InputStreamReader(new FileInputStream(file), "gb2312")){
reader.read(res);
}
System.out.println("组合使用:" + new String(ch));
}
}
其实,在实际的开发中放置乱码发生的核心办法是:统一开发环境。其实这个是最好的办法了,只要保证你的环境,和你合作开发的朋友的环境,各种资源,数据库等等。如果保证了这些编码的统一,基本上是不会出现乱码的。
尾记
在java的IO系统中除了上面图片所展示的之外,还有一个使用非常频繁的类:RandomAccessFile类。这个类很有意思,它是自成一派的,是一个自我独立的类。在后续的博文中会介绍到它。而且在本篇叙述中,只涉及到很少的代码实现输入输出,我想在后面在详细的描述如何正确的使用它们。



